基于hadoop2.7.1集群
系统为centos 6.4 ,64bit
1.安装scala环境
下载并安装scala,scala-2.11.8.tgz下载地址。
解压scala-2.11.8.tgz并配置环境变量:
之前需要安装并配置java;
切换到/usr/local目录:#cd /usr/local;
解压scala-2.11.8.tgz :#tar -xzvf scala-2.11.8.tgz;
更名:#mv scala-2.11.8 scala,使用简单;
配置环境变量:#vim /etc/profile,填写内容
export SCALA_HOME=/usr/local/scala
export PATH=:$PATH:$JAVA_HOME/bin:$SCALA_HOME/bin
使得环境变量生效:#source /etc/profie;
2. 安装spark
下载spark版本(基于hadoop2.x的yarn集群):spark-1.6.1-bin-hadoop2.6.tgz下载地址
切换到/usr/local目录:#cd /usr/local;
解压spark-1.6.1-bin-hadoop2.6.tgz:#tar -xzvf spark-1.6.1-bin-hadoop2.6.tgz
更名:#mv spark-1.6.1-bin-hadoop2.6 spark
配置环境变量:#vim /etc/profile,填写内容
export SPARK_HOME=/usr/local/spark
export PATH=:$PATH:$JAVA_HOME/bin:$SCALA_HOME/bin:$SPARK_HOME/bin:$SPARK_HOME/sbin
使得环境变量生效:#source /etc/profie;
3.配置spark
切换到/usr/local/spark/conf目录:#cd /usr/local/spark/conf;
添加配置文件:
#cp spark-env.sh.template spark-env.sh
编辑配置,添加如下代码:#vim spark-env.sh
export JAVA_HOME=/usr/local/jdk
export SCALA_HOME=/usr/local/scala
export HADOOP_CONF_DIR=/usr/local/hadoop271/etc/hadoop
export SPARK_MASTER_IP=192.168.31.101
export SPARK_EXECUTOR_MEMORY=1G
export SPARK_YARN_APP_NAME=SPARK
#cp slaves.template slaves
添加集群机器配置:vim slaves
h2m1
h2s1
h2s2
slaves内添加,每个机器的ip或者在hosts文件中对应的hostname,每个ip一行。
将spark目录复制到其他slave机器
#scp /usr/local/spark/* root@h2s1:/usr/local/spark
#scp /usr/local/spark/* root@h2s2:/usr/local/spark
将/etc/profile复制到其他机器
#scp /etc/profile root@h2s1:/etc/
#scp /etc/profile root@h2s2:/etc/
在每个机器上执行source /etc/profile,使得环境变量修改生效。
4.启动hadoop集群
启动命令:start-dfs.sh
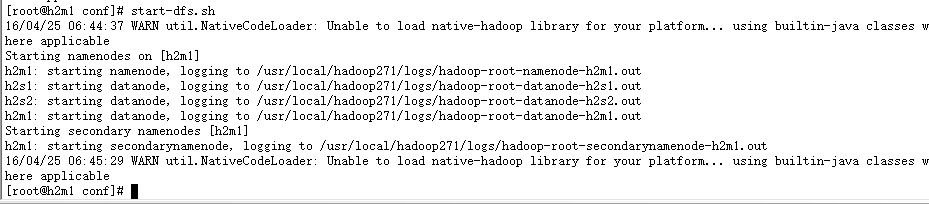
启动yarn集群:start-yarn.sh

进程查看:#jps
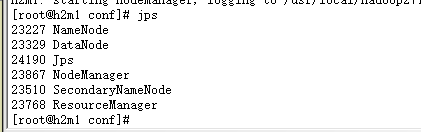
5.启动spark集群
因为hadoop集群和spark集群在同一master机器上,并都添加进环境变量,因此对spark的启动脚本进行更名,以避免重复。
#mv start-all.sh start-spark-all.sh和#mv stop-all.sh stop-spark-all.sh
启动命令:#start-spark-all.sh

进程查看:jps
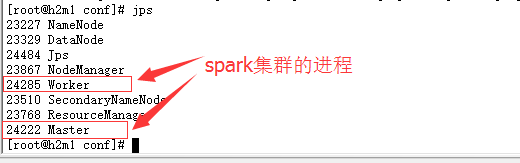
WebUI验证:
Master URL:http://h2m1:7777/
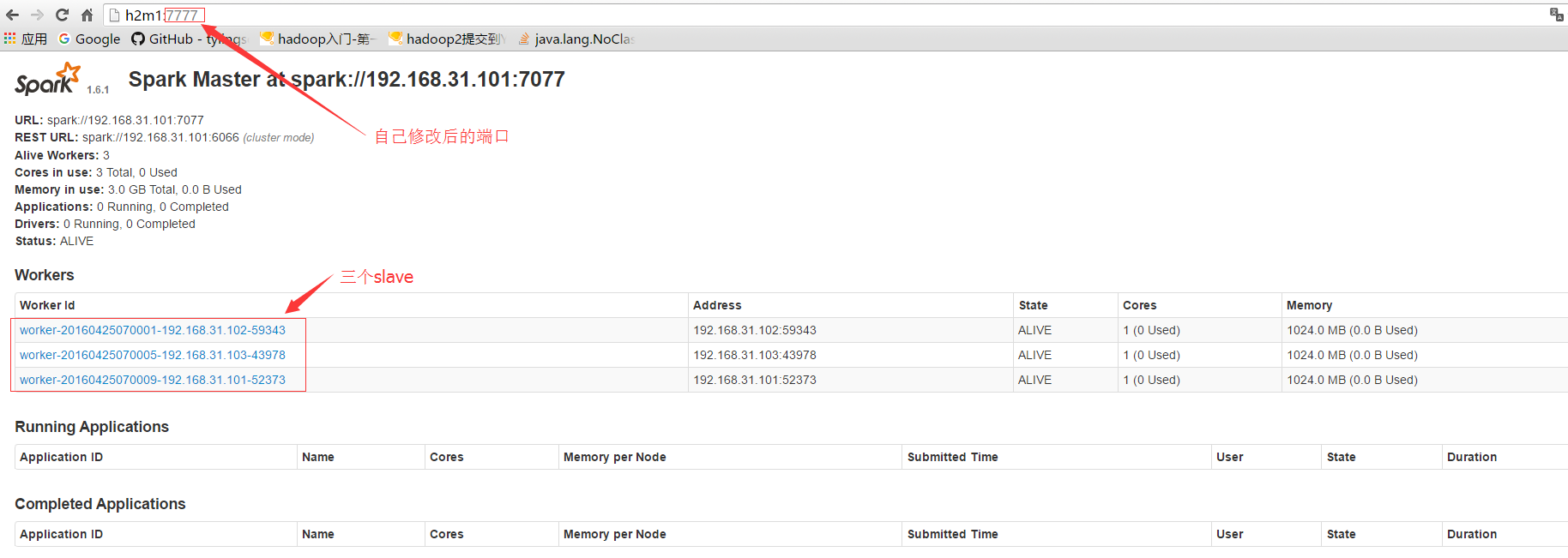
Worker URL:http://h2m1:8081

