准备环境
运行环境
- hadoop2.7.2 集群环境(三个节点,h2m1,h2s1,h2s2)
- jdk 1.7.0_75版本
- centos6.5系统
开发环境
- windows7 企业版 64位
- 8G内存
- eclipse 4.5
- 插件 hadoop-eclipse-plugin-2.6.0.jar,用于查看远端的HDFS上的文件
将Linux上成功配置了YARN集群的相同hadoop版本(hadoop2.7.2)下载一份到开发机器win7上, 下载hadoop2.6(x64)V0.2 或者hadoop.dll、winutils.exe 或者github上的项目将其bin目录下文件或直接文件覆盖到Hadoop2.7.2(windows开发调试环境)的bin下
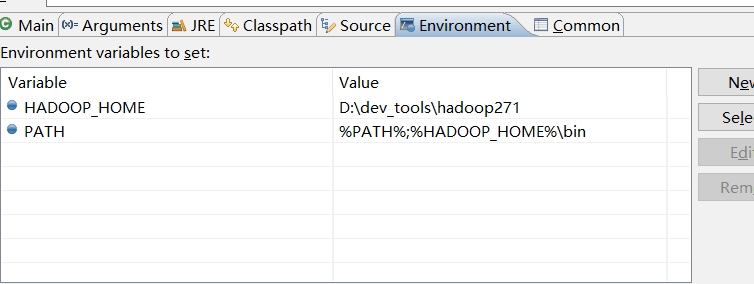
配置HADOOP_HOME和PATH两个系统环境变量。为了避免不生效,重启电脑。
如果还是会报错:找不到/tmp/hadoop-yarn/staging/JING/.staging/job_1481726235168_0009/job.splitmetainfo,
那就在Eclipse中项目属性中也配置以上的环境变量。
使用maven创建项目 并编写MR程序
Mapper和Reducer代码参考:编写MR程序
完整本地调试的主Job类
package cn.followtry.hadoop.demo.v2.mr;
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.GenericOptionsParser;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import cn.followtry.hadoop.demo.hdfs.HDFSOper;
import cn.followtry.hadoop.demo.util.DebugConfUtil;
/**
*
* brief-hadoop-demo/cn.followtry.hadoop.demo.v2.mr.WordCountV2
*
* @author jingzz
* @since 2016年12月14日 上午10:03:48
*/
public class WordCountV2 {
private static final Logger LOGGER = LoggerFactory.getLogger(WordCountV2.class);
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
Configuration conf = new Configuration();
String[] otherArgs = new GenericOptionsParser(conf, args).getRemainingArgs();
if (otherArgs == null || otherArgs.length < 2) {
System.out.println("用法:\n" + " 至少需要两个参数,最后一个为输出目录,其他为输入文件路径");
System.exit(-1);
}
StringBuilder inputPaths = new StringBuilder();
String outpathDir;
int len = otherArgs.length - 1;
for (int i = 0; i < len; i++) {
inputPaths.append(otherArgs[i]);
if (i < len - 1) {
inputPaths.append(",");
}
}
outpathDir = otherArgs[len];
// 检查输出目录是否存在,存在则直接删除目录
HDFSOper.rmExistsOutputDir(outpathDir);
// 只有在当前系统为windows是设置该debug配置
String osName = System.getProperties().getProperty("os.name").toLowerCase();
if (osName.contains("windows")) {
LOGGER.info("运行在windows平台,需要设置配置");
String jarPath = "d:\\mapreduce.jar";
DebugConfUtil.setLocalDebugConfiguration(jarPath, conf);
} else {
LOGGER.info("运行在{}平台", osName);
}
Job job = Job.getInstance(conf, "wordCount v2 demo 2");
job.setJarByClass(WordCountV2.class);
job.setMapperClass(WordCountMapV2.class);
job.setCombinerClass(WordCountReduceV2.class);
job.setReducerClass(WordCountReduceV2.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
FileInputFormat.setInputPaths(job, inputPaths.toString());
FileOutputFormat.setOutputPath(job, new Path(outpathDir));
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}
提取的工具类DebugConfUtil.java
package cn.followtry.hadoop.demo.util;
import org.apache.hadoop.conf.Configuration;
/**
* brief-hadoop-demo/cn.followtry.hadoop.demo.util.DebugConfUtil
* @author
* jingzz
* @since
* 2016年12月15日 下午12:32:02
*/
public class DebugConfUtil {
private DebugConfUtil() {
}
/**
* 设置win本地调试提交MR程序到远程YARN集群上的配置信息
* @author jingzz
* @param jarPath 生成的jar的位置
* @param conf 传入Configuration类
*/
public static void setLocalDebugConfiguration(String jarPath, Configuration conf) {
conf.set("mapreduce.framework.name", "yarn");
/*
* 避免/tmp/hadoop-yarn/staging/JING/.staging/job_1481726235168_0009/job.splitmetainfo找不到的错误
* value为hdfs-site.xml的dfs.namenode.rpc-address.ns1属性指定的值。
*/
conf.set("fs.defaultFS", "hdfs://h2m1:8220");
//避免ExitCodeException exitCode=1: /bin/bash: line 0: fg: no job control
conf.set("mapred.remote.os", "Linux");
conf.set("mapreduce.app-submission.cross-platform", "true");
/*
* 避免Retrying connect to server: 0.0.0.0/0.0.0.0:8030
* 一般为默认设置,value为主yarn的resourcemanager节点的host:port
*/
conf.set("yarn.resourcemanager.scheduler.address", "h2m1:8030");
conf.set("yarn.resourcemanager.address", "192.168.2.201:8032");
/*
* 避免java.lang.ClassNotFoundException: Class cn.followtry.hadoop.demo.v2.mr.WordCountMapV2 not found问题
* 日志提示:No job jar file set. User classes may not be found. See JobConf(Class) or JobConf#setJar(String)
* 所以不管是在Eclipse中直接调试运行还是上传到Yarn集群,都需要先打成Jar包。
* "mapred.jar"不需要动,只要将"d:\\mapreduce.jar"处替换为打好包的jar的位置。
* "mapred.jar" 已经过期,请替换为"mapreduce.job.jar"
*/
//conf.set("mapred.jar", "d:\\mapreduce.jar");
conf.set("mapreduce.job.jar", jarPath);
}
}
为了在本地远程调试和提交到远程YARN集群上执行间最小的变动,将输入输出配置为参数执行。如下:
项目右击 –> Run As –> Run Configurations –> Arguments –> 在下面空白框内设置input和output两个实际的参数 –> Run 。
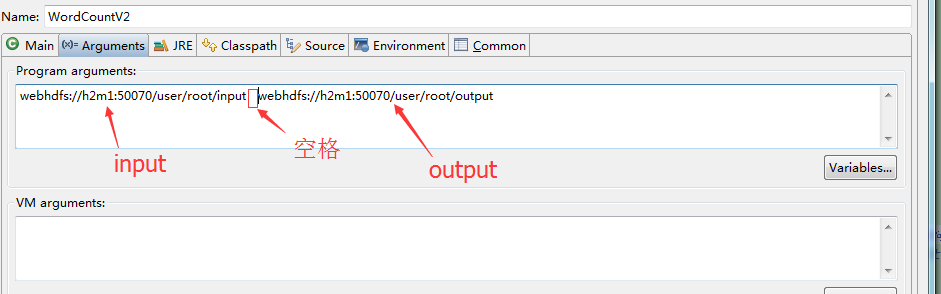
这样就可以在本地调试MapReduce程序了。
执行结果:
目录webhdfs://h2m1:50070/user/root/output不存在
INFO - 目录webhdfs://h2m1:50070/user/root/output不存在
INFO - Connecting to ResourceManager at /192.168.2.201:8032
WARN - Hadoop command-line option parsing not performed. Implement the Tool interface and execute your application with ToolRunner to remedy this.
INFO - Total input paths to process : 2
INFO - number of splits:2
INFO - Submitting tokens for job: job_1481717720063_0021
INFO - Submitted application application_1481717720063_0021
INFO - The url to track the job: http://h2m1:8088/proxy/application_1481717720063_0021/
INFO - Running job: job_1481717720063_0021
INFO - Job job_1481717720063_0021 running in uber mode : false
INFO - map 0% reduce 0%
INFO - map 50% reduce 0%
INFO - map 100% reduce 0%
INFO - map 100% reduce 100%
INFO - Job job_1481717720063_0021 completed successfully
查看执行结果
可以通过已经配置好的Hadoop-eclpse-plugin查看/user/root/output下的part-r-00000结果文件。
问题解决参考:
- Exceptionin thread “main” java.lang.UnsatisfiedLinkError:org.apache.hadoop.util.NativeCrc32.nativeComputeChunkedSumsByteArray(II[BI[BIILjav
- Eclipse下配置应用运行的环境变量
- hadoop-eclipse插件配置
- 编译Eclipse中hadoop插件hadoop2x-eclipse-plugin
- java.lang.RuntimeException: java.lang.ClassNotFoundException的原因
- YARN中JVM的重用功能(UBER)
版权声明:本文由 在 2016年12月15日发表。本文采用CC BY-NC-SA 4.0许可协议,非商业转载请注明出处,不得用于商业目的。
文章题目及链接:《windows下Eclipse远程调试运行MR程序》
