伪分布式运行hadoop自带Wordcount程序
[root@h2m1 ~]# hadoop jar /opt/local/hadoop271/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.1.jar wordcount hdfs:///user/root/input hdfs:///user/root/output
运行截图:


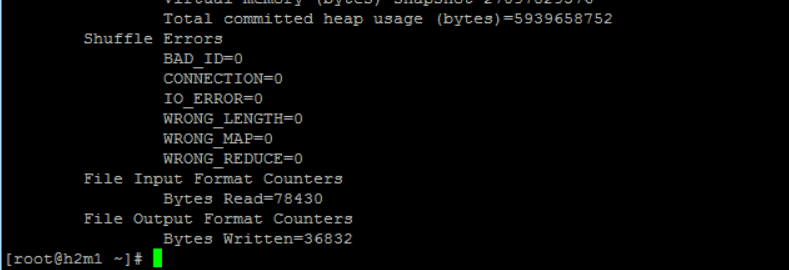
web页面中任务执行结果:

hadoop设置成功之后,只是对master格式化
不需要对datanode节点格式化,格式化实质上说对NameNode的元数据区进行格式化。
启动成功namenode和yarn集群的标识
截图:
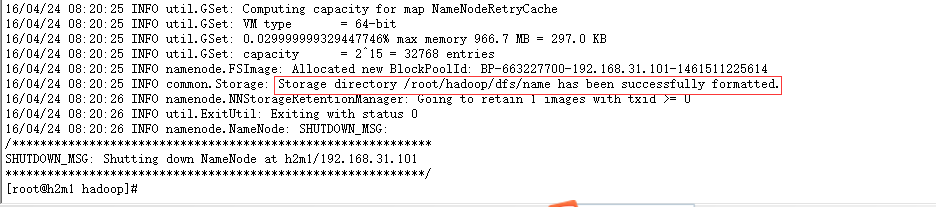
namenode格式化成功:
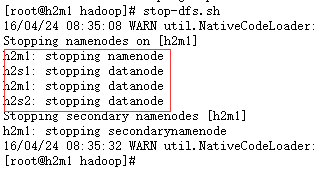
namenode、datanode和secondary namenodes停止成功:
集群yarn启动成功:

namenode -format 再次格式化时错误
每次使用hdfs namenode -format格式化文件系统时会产生新的namenodeId,如果自定义的temp目录或datanode和namenode目录data、name不为空就会失败,只要将该部分内容清空即可。
